Make the Most of your Mental Real Estate And Learn Words by the Hundred
Overlay scenes and stack them to pack your memory palace with countless words
Published on
Part of the series: Illustrating Memory Palaces with AI
This series deals with the optimization of memory palaces. If you're wondering what they are, head to my introductory series, "The Power of Memory Palaces" and "How to Use Memory Palaces for Long-Term Vocabulary Retention"
Why I Bother with Overlays
In my previous post, I showed how changing color and style across scenes helps retention, and I suggested a simple workflow anchored in an Obsidian canvas. During review, I mentally overlaid the AI-generated scene (gpt-image-1, Ideogram, or another model) onto the photo of the associated locus. That mental superposition works—but it’s needless effort. So I built a quick montage: combine the decor and the visualization support in one image, and let my eyes do what I was asking my mind to do.
Automating the Overlay at Scale
First, I generated a small script with ChatGPT to batch the overlays. It scales: think a hundred location photos and as many scenes, done quickly, no need for Gimp or any heavyweight editor.
The Immediate Win
By fusing decor and scene, the superposition I was doing in imagination becomes visible. In early learning, instead of switching between my gallery of photographs and a canvas of scenes, I focus a single stream of images. When I “walk” mentally past the wallaby enclosure’s grid, the scene pasted onto it fires instantly.

Why Not Inpaint the Locus Directly?
You could ask: why not use ChatGPT’s image editing, feed it the background photo, and instruct it to inpaint the emblems directly? That aligns closely with classic method-of-loci rules: the walker finds elements distributed in the decor, not hung as a painting inside the decor. And yes, gpt-image-1’s editing is very strong; the current leaderboards bear this out:
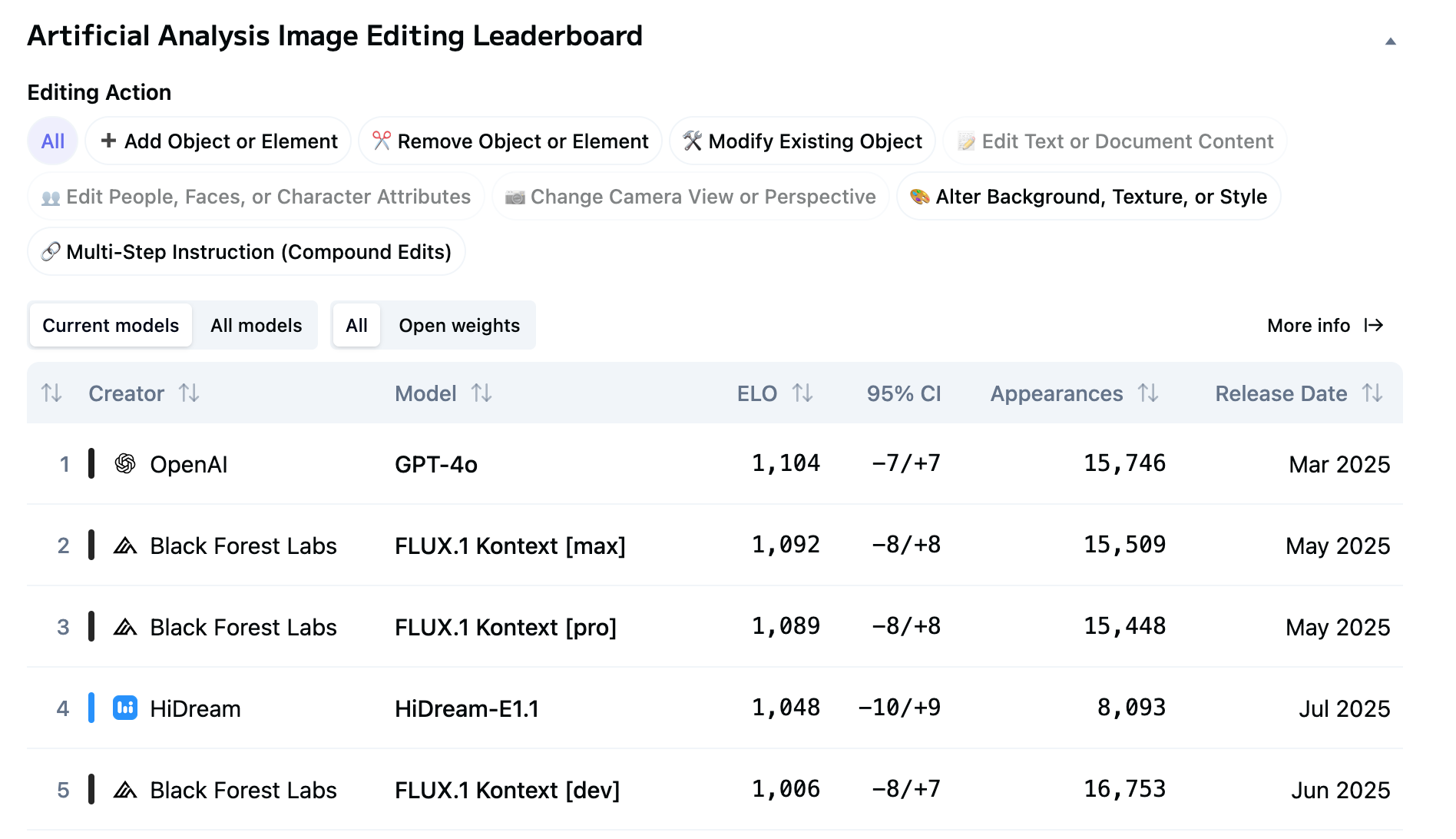
What I Saw in Practice
The results are impressive. Some small artifacts appear (mangled graffiti on the gate here, a branch silhouette there), but the wallaby-enclosure photo remains perfectly recognizable. All essential elements survive, with only minor deviations from the ideal output. One oddity: a small moon statue duplicated—crescent above, full below—but nothing that undermines function.

Why I Still Favor Overlay-First
I came to the direct-insertion idea while drafting this very piece. If I were starting today, I would still choose my original pipeline: generate the scene first, overlay it second. One reason dominates—compression: the ability to pack multiple scenes into a single locus without losing recall speed.
The Scarcity of Loci Is Real
In "How to Use Memory Palaces for Long-Term Vocabulary Retention", I recommended one scene per station. Why change now? Because loci are finite. The Jardin des Plantes is not boundless. Before I adopted AI-painted illustrations, my scenes needed space to breathe, which forced gaps between adjacent decors. Circling the wallaby enclosure, I could harvest roughly a dozen loci—about sixty words. Across the garden I hold more than a hundred well-spaced locations. If I ventured into the Menagerie, I could add a few dozen more.
But I need to house two to three thousand Sanskrit words, with extra headroom for verb primitives maybe. Yes, the Luxembourg gardens would also serve, and I could build there. Still, I became curious: could I compress more into each station and retain clarity? It's a pity to use
The Strip-Collage (a.k.a. “Lasagna”) Approach
I started slicing each scene into a horizontal strip and assembling five strips into one composite, then overlaying that composite on the decor. Five scenes; one locus.

How I Study the Lasagna
During initial study, I keep both the full scenes and the lasagna in view. That bonds each scene to the station. Then I stare at the lasagna and trace a pathway across the five layers—left to right or top to bottom—until a set of linkages hardens.
In the example above, the dragon seems to drip honey (strip 1) onto the armchair (strip 2), which leans against the wooden churn (strip 3). On the right, the jester (still strip 3), the statue (strip 4), and the monkey paws (strip 5) coalesce into a weird but unmistakable character. These hooks give me a path.
A Sideways Nod to the Surrealists
It feels like the surrealist game called exquisite corpse (French cadavre exquis): each contributor draws a band without seeing what comes before. The juxtapositions produced as a consequence are improbable but memorable.

What I Actually Memorize
There are three layers of learning:
- Scene content and symbols. I rehearse each emblem and its meaning.
- Strip order inside the lasagna. I fix the stack and my traversal route.
- The decor itself. I bind the lasagna to its station within the palace.
When I walk mentally from locus to locus, I let the five fifths float before me, unfold them in sequence, name the emblems, and climb or descend between strips along the pre-set circuit.
Why Direct Inpainting Breaks at Scale
This is where direct insertion into the photo falters. Editing a locus to place half a dozen emblems? A model such as gpt-image-1 copes. Thirty emblems? I am convinced it will drop some. Iterative insertion (five at a time) tends to regress: as new emblems are added, earlier ones would disappear for sure. With patient hand-holding in the web UI, one could maybe eke out the expected result. But for serial production, low frustration, and repeatability, I need an API-friendly workflow. The overlay-first pipeline wins on throughput and reliability.
The Payoff
- Density: Five scenes per station without muddling recall.
- Fidelity: decor remains immediately recognizable—my anchor is stable.
- Speed: Study paths are explicit and rehearseable.
- Scale: Batch rendering, minimal friction, no dependency on delicate edits.
What Comes Next
This concludes the first series on what AI can do for vividness and sharpness in memory-palace visualization. Next, I’ll turn to a long-standing goal: a method to reconcile Anki with the method of loci—spaced repetition without abandoning the walk.



